
FileMan 22, I'd like you to meet the world. World, this is FileMan 22.
First, a little context. FileMan 21 was released in April, 1994, so 22 will have been almost four years in development. It is currently in alpha test and is planned for release in March.
The core of FileMan 22 is the indexes and keys project. The more complete support for keys and indexes should help you better import, export, distribute, and map data in your FileMan files with external systems in a reliable way.
I designed and began this work under the guidance of Maureen Hoye, then transitioned it over to Tami Winn and Michael Ogi, under the guidance first of Ms. Hoye and then, for most of this time, Jean Sheppard. Ms. Winn and Mr. Ogi have done the lion's share of the work on this project. In addition, Skip Ormsby has fixed many bugs and George Timson has given us some great improvements in FileMan's user interface.
Overall, FileMan 22 was almost as difficult a job as 21. With the key and index project, we had to enter and modify the architecture of almost all the classic calls and options including the DBS calls added in FileMan 21 and the Data Dictionary (DD) itself (the very heart of FileMan). We've changed the user interface to screen-orientation in the five major options that manipulate the DD, and we've added more calls to the DBS.
The work falls into three categories: user interface, indexes, and keys. This article only has room to mention some of the changes. An in-depth discussion will follow in future articles.
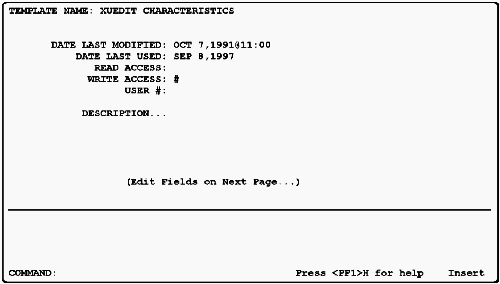
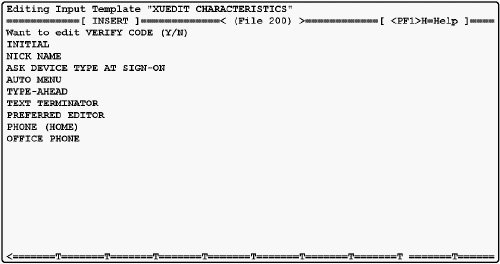
George Timson revised the DD manipulation options for templates, fields, and files so you can choose between scrolling and screen modes. Here are some sample captures of each.
1. Template Edit (new option on the Utility menu, Figure 1). The opening screen:
2. Modify File Attributes: Figure 3.
4. Audit Display Improvements.
Also, check out the audit display, described by Mr. Timson in the previous Focus on FileMan (M Computing vol. 6, no. 5).
To introduce support for keys (essential for improving interoperability with external systems, especially relational ones), we needed support for compound indexes, and the work for compound indexes was best handled by solving most of the other index problems first. We did not get everything (e.g., case-independent indexes, although the new hooks make it easier than it was), but we got most of it.
1. Definitions. An Index will mean an inverted file, that is, the actual subscripted data (such as the B index). A Cross-Reference (or xref) will mean the code and logic used to define and create an index (or fire a trigger, or send a bulletin, etc.).
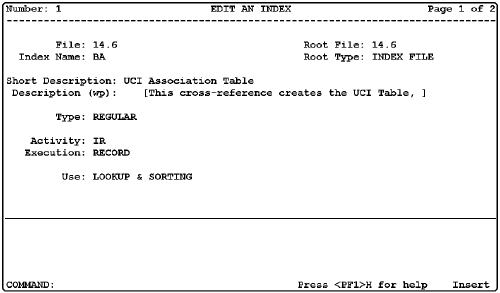
2. The Index File and the Cross-Reference Subfile. Cross-references have been defined in the Cross-Reference subfile of the Field subfile of the DD, where it is not directly accessible by pointer. We need to have Keys point to their related Indexes, so we've created a new Index file in the DD for defining cross-references and the resulting indexes. It is fully FileMan-compatible and is in fact recursively defined-it defines its own cross-references and indexes. FileMan will honor cross-references defined in either file-the classic Cross-Reference subfile or the new Index file. However, developers are encouraged to shift toward the new Index file because it has so many more features, as described below. In 22, it supports Regular or M cross-references, but others are coming in the future.
3. Cross-Reference a File or Field (replaces Cross-Reference a Field). Here's page 1: Figure 5.
4. Collation Sequence. With 22, any index subscript can be flagged for 'backward' collation sequence so the data will be stored in its natural form but traversed backward. This replaces inverse dates.
5. Maximum Subscript Length. A new Maximum Length subscript attribute lets the developer set the length of a data subscript in a regular index. This replaces FileMan's old 30 character limit.
6. Lookup Prompt. Each index subscript can be assigned a prompt to be used for entry of the lookup value during classic FileMan lookup ^DIC calls. This replaces using the name of the subscripted field, especially since subscripts no longer need to be field values.
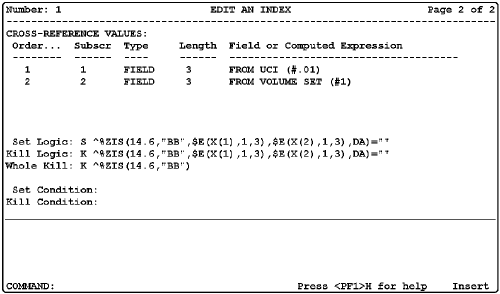
7. Compound Indexes. FileMan now supports otherwise regular indexes with more than one data subscript. They are defined once for the source file rather than for every field in the index. This replaces the awkward compound indexes of the past that were hand built using MUMPS cross-references.
8. Better Segmentation of Cross-Reference Logic. Cross-References defined in the Index file have a new structure.
First, use the Index file to tell FileMan what fields you want and he fetches it for you and preloads it into an X array. The values you need are numbered in the order you request and X is subscripted by that same order number.
Second, describe the transform associated with each cross-reference value in the Index file and FileMan will apply it for you (see item 9).
You may assume any cross-reference value with a lower order number is already loaded into the X array and transformed before the logic for the current cross-reference number executes. You can use earlier values to help transform, screen, or compute later ones.
Third, for Regular cross-references, tell the Index file which values go into which subscripts and FileMan will build the set and kill logic for you.
You don't need to put all the cross-reference values into subscripts; some cross-reference values will just be used to screen or transform values that do go into subscripts. An M cross-reference need not generate an index at all, in which case none of the cross-reference values are given subscript assignments.
9. Cross-Reference Value Transforms. Two new fields, Transform for Storage and Transform for Display, can be set on index subscripts to store M code that transforms the field value between user-friendly and index-friendly forms. FileMan lookup routines will try to find entries in the index using the lookup value as entered by the user, but will also fire the Transform for Storage on the lookup value and try to find a match in the index with the resulting value. Then for any match found, the index value will be passed back through the Transform for Display code before the user sees it.
You can also use the Transform for Storage field alone to define a subscript that is derived from a field value. For example, the current BS5 index on the Patient file is subscripted by the last letter of a Patient's name, followed by the last four digits of the social security number. This subscript value could be created by setting up Name and SSN as cross-reference values, then assigning the second of them (based on the Order field) a Transform for Storage that combines it properly with the other field value and assigning it the proper subscript position (1 in this case).
Note: this is where to put your case sensitivity transforms until we offer direct support.
10. Computed Cross-Reference Values. When you define a cross- reference value in the Index file you can declare whether or not it is derived from a field value, and if not, you can enter the pure M code used to generate the value. Typical examples are the current time (from $H) for timestamping or job number ($J) for logging.
11. Record-level Firing of Cross-References. For efficiency, cross-references can be flagged to fire at the record level, so that instead of firing the set and kill logic as each field in the index is edited, FileMan waits until the user has finished editing an entry in a file or subfile before firing the set and kill logic. This is the default for compound indexes, because as described above it makes them more efficient.
12. Set and Kill Conditions. You can screen whether the set and kill logic should fire. The 'before' and 'after' values of fields are available to this logic in local arrays. You can use the screens to create indexes with a subset of the file's entries or intelligent M cross-references.
13. Activity Field. You can tell FileMan with the Activity field whether the set and kill logic should be fired during re-cross- referencing or package installation (KIDS).
14. Kill Entire Index Code. In some situations, such as re-cross-referencing or package installs, FileMan would prefer to do the equivalent of "blow away the entire index at once" rather than traverse the entire file firing kill logic for each entry. This cross-reference logic is now explicitly stored in the Index file so developers can build their own for M cross-references, when some such conceptual equivalent exists.
Keys are essential to using file entries effectively. They address the fundamental abilities of knowing 1) the identity of a given entry and 2) whether or not it is already in any given file. Without knowing both you can't create files with entries guaranteed to be unique (such as a Patient file, in which you'd really prefer to keep all a patient's data in one place).
Keys are also essential to using fields effectively because a vital component of field integrity is whether it is required or allowed to be optional. Fields comprising a key are required.
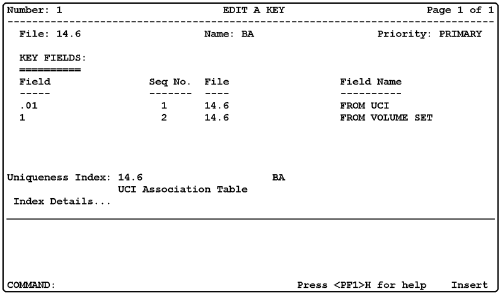
1. Definitions. A key is a concise set of fields that uniquely identifies an entry in a file.
By "uniquely identifies," we mean no entry in the file will have the same combination of values for those fields as any other entry.
By "concise set," we mean a group from which you could not remove any field without destroying the ability of that group to uniquely identify entries in that file. A file may have more than one key, for example, states can be identified by any number of different keys (name, abbreviation, order of admission to the union, current governor, state flower, etc.). Choose one of the keys, preferably the most user-friendly one, to use for all built-in database operations (such as software distribution), and name it the Primary Key. The remaining keys are called Secondary or Alternate Keys, but they are enforced just as strongly as the Primary key.
2. Key Definition (new option on the Utility menu): Figure 7
3.Uniqueness Index. FileMan must have an index with the same fields as the key and in the same order to enforce the uniqueness of the key. Order your key fields from most unique to least unique, to make your uniqueness index as broadly useful as possible, and synchronize the name of your key with its uniqueness index.
We have allocated four new IENs in the Language file: Finnish = 5 (Hi Hellevi), Italian = 6, Arabic = 10, and Russian = 11. FileMan does seem to be appreciated abroad. Also, although the DIFROM Server, which powers KIDS, has been upgraded to handle keys and indexes, the classic DIFROM itself has not, so unless and until someone does the work to upgrade it, steer clear.
Keys and indexes are vital to good file design, so you may expect to see a great deal written about them in this column in the years to come, but I hope this introduction helps you start off on the right foot.
If you have questions or comments about FileMan 22 or topics you would like to see addressed in this column, send email to: G.FMTEAM@FORUM.VA.GOV, or write to: Infrastructure Maintenance Team, VACIOFO-San Francisco, Suite 600, 301 Howard Street, San Francisco, CA 94105.
The ubiquitous Rick Marshall (toad@eskimo.com) is a hardhat (www.hardhats.org) who works at the VA's Puget Sound Health Care System.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}